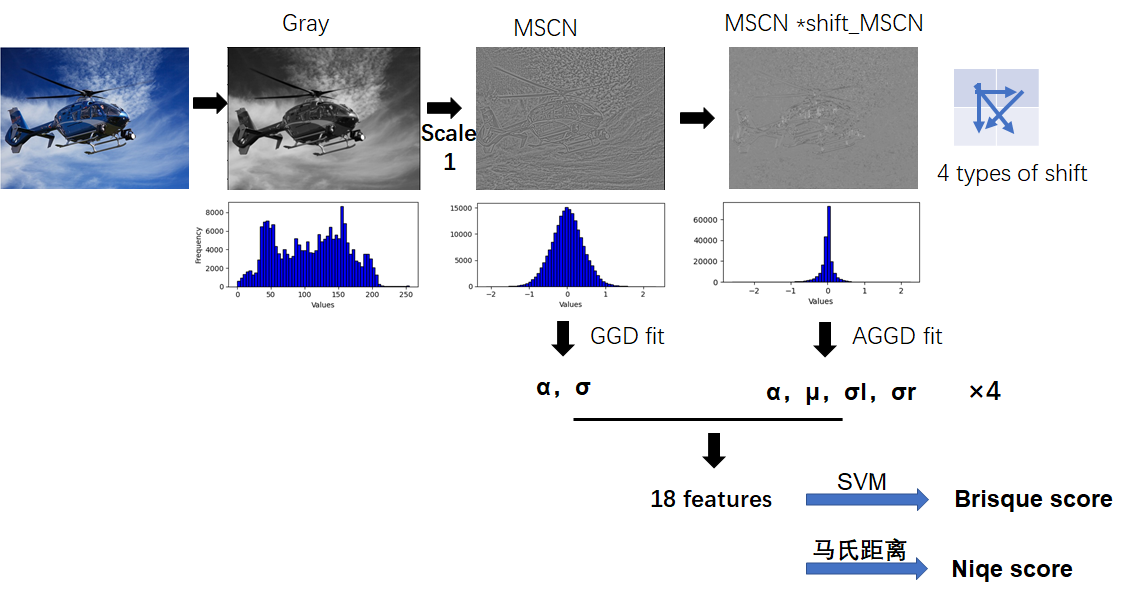
NIQE 自然图像质量评估器(Natural Image Quality Evaluator)
IQA model 分类
在图像质量评估(IQA)领域,OA、OU、DA和DU是描述评估模型特性的术语,它们分别代表:
- OA (Opinion-Aware): 意见感知型。这种类型的IQA模型在训练阶段使用了人类对失真图像的评分数据。换句话说,这些模型通过学习人类对图像质量的主观评价来预测图像质量。OA模型能够评估它们在训练数据中见过的失真类型。
- DIVINE
- CBIQ
- LBIQ
- BLIINDS
- BRISQUE
- OU (Opinion-Unaware): 意见不感知型。与OA模型不同,OU模型在训练时不使用人类对失真图像的评分。它们不依赖于人类对特定失真类型的主观评价,而是通过其他方式来评估图像质量。
- DA (Distortion-Aware): 失真感知型。DA模型在设计时考虑了特定的失真类型,它们通过训练来识别和评估这些特定的失真。这些模型对它们训练中包含的失真类型有更好的评估能力。
- DU (Distortion-Unaware): 失真不感知型。DU模型在设计时不针对任何特定的失真类型。它们不使用关于失真的先验知识,而是依赖于自然图像的统计特性来评估图像质量。
- SSIM
或许可以这么理解 opnion 类似于mos打分数据集, distortion类似于某些图像问题数据集,比如flick 、 contour 、purple firing 等. aware 表示需要相关数据库获取某些统计信息,给模型提供预先的参数,而 unaware 表示在没有相关数据集训练的情况下,也能进行评估
NIQE是a kind NSS-driven blind OU-DU IQA model,尽管NIQE也是用了BEISQUE的features
BRISQUE 需要在提取特征后接一个 natural 和distored 图像的分类器,这个分类器是需要训练的. 因此BRISQUE属于 OA
NIQE 虽然也用了BEISQUE的 mscn features, 在拟合MVG的时候貌似也用了自然数据获得的MVG 平均参数, 但一方面 MVG参数的获得可来源其他数据集,获得一个统计学知识,不需要再学习,一方面它没有对mos结果进行拟合,它知识统计了这些图像的某些特征均值.因此可以认为它是一个 OU的方法. 同理也是DU
NIQE
NIQE(Natural Image Quality Evaluator)是一种基于自然场景统计特征的无参考图像质量评估指标。其使用高斯混合模型(GMM)来建立自然图像特征的概率分布,并用该分布来评估输入图像的质量分数。
关于 NIQE的解释,这篇blog有不错的介绍,可以参阅:
纹理区域
https://blog.csdn.net/weixin_45682889/article/details/108739906
文中提到,人们对于纹理处的模糊变化相较于平坦区域敏感. 因此需要筛选图像块.
Since humans appear to more heavily weight their judgments of image quality from the sharp image regions.
We use a simple device to preferentially select from amongst a collection of natural patches those that are richest in information and less likely to have been subjected to a limiting distortion.
筛选标准是:边缘更锐利的,包含信息内容更丰富的。
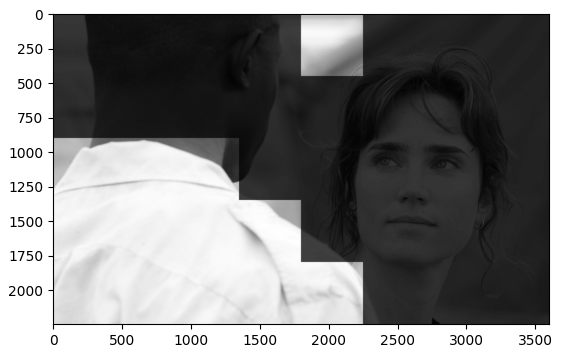
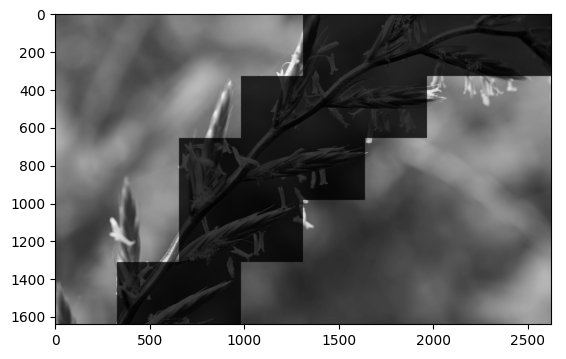
在归一化后,筛选前,作者将图像分成大小为PxP的若干个图像块(P=96),索引为b = 1,2,3,…,B
再对每个图像块求平均方差(也就是下文提到的锐利程度):这里的σ就是计算MSCN用在分母的σ
- 如何筛选呢?
作者将所有图像块的最大锐利程度的 p 倍设为阈值,其中p ∈ [0.6, 0.9],论文中取值为 0.75。将大于阈值的图像块保留,小于阈值的图像块淘汰掉。

测试结果
感觉8*8 patch 上粗略分比较合适
patch : 16*16
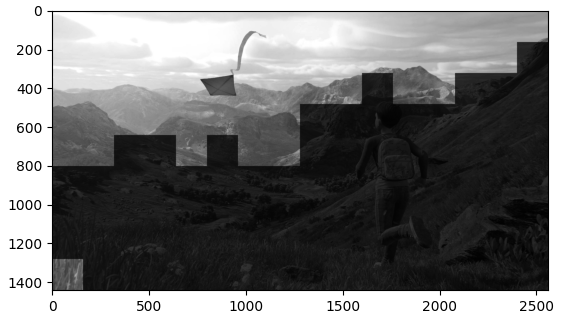

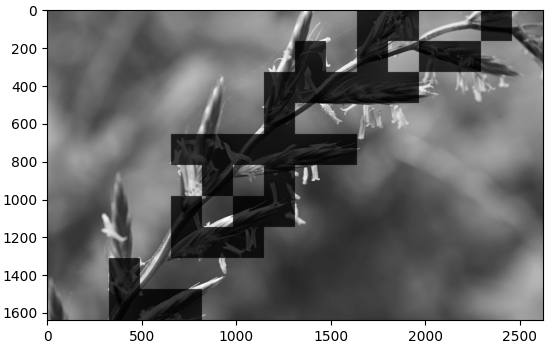
patch 8*8

NIQE指标
通过将自然图像块与MVG模型密度函数拟合,可以得到一个简单的NSS特征模型,MVG模型(Multivariate Gaussian Model)密度函数为:
式中( x 1 , . . , x k ) 是BRISQUE的NSS特征。v 与Σ 分别表示MVG模型的均值与协方差矩阵,可由标准最大似然估计得到,可通过统计自然图像得到,并存储下来
用NSS特征模型与提取自失真图像特征的MVG间的距离来表示失真图像的质量,即最后的NIQE指标:
其中v*1,v 2 ,Σ1,Σ2分别表示自然MVG模型与失真图像MVG模型的均值向量和协方差矩阵。
马氏距离 Mahalanobis distance
这里的NIQE指标 是统计学概念中的马氏距离 Mahalanobis distance
马氏距离实际上是欧氏距离在多变量下的“加强版”,用于测量点(向量)与分布之间的距离。
什么情况下适用马氏距离?
当需要度量点(向量)与多变量分布之间的距离时,如果直接采用欧式距离,衡量的是两点之间的直接距离(点与分布之间的欧式距离,指的是向量x与变量空间中心的距离),而没有考虑数据的分布特性。
而采用马氏距离,在计算中对协方差进行归一化,则可以规避欧式距离对于数据特征方差不同的风险,从而使所谓的“距离”更加符合数据分布特征以及实际意义。1
如下图所示,这是是两个变量的简单散点图。左图是两个变量之间不相关,Point 1和Point 2与分布中心的距离相等。右图是两个变量之间呈正相关。即随着一个变量(x轴)的值增加,另一变量(y轴)的值也增加。
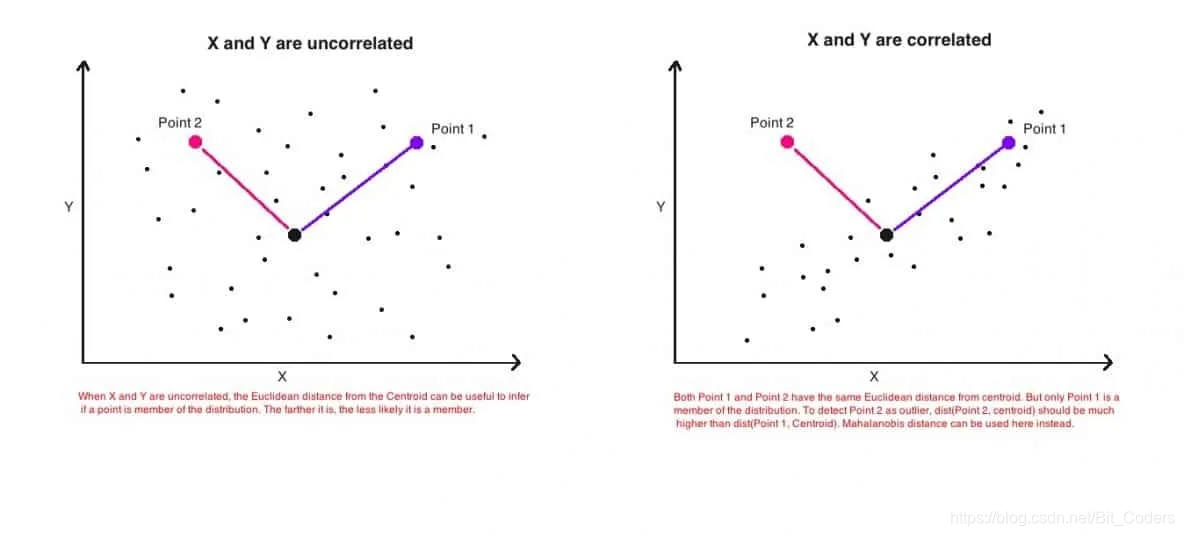
从几何上说,Point 1和Point 2两个点与分布中心的距离相等(欧几里得距离)。但是,即两点到分布的欧几里得距离相等,但实际上只有Point 1(蓝色)更容易采样获得,而point2 的概率很低。
这是因为,欧几里得距离仅是两点之间的距离,它不考虑数据集中的其余点的分布情况。因此,它不能用来真正判断一个点实际上与点的分布有多接近。所以我们需要的是更健壮的距离度量标准,该度量标准可以精确地表示一个点与分布之间的距离。
计算公式
向量x到一个均值为μ ,协方差为S 的样本分布的马氏距离计算如下:
直观解释
( x − μ )本质上是向量与平均值的距离。然后,将其除以协方差矩阵(或乘以协方差矩阵的逆数)。
这实际上是多元变量的常规标准化(z =(x – mu)/ sigma)。也就是说,z =(x向量)–(平均向量)/(协方差矩阵)。
如果数据集中的变量高度相关,则协方差将很高。除以较大的协方差将有效缩短距离。
同样,如果X不相关,则协方差也不高,距离也不会减少太多。
因此,它有效地解决了规模问题以及前文中谈到的变量之间的相关性。
如果协方差矩阵为单位矩阵,即样本向量之间独立同分布,就得到欧式距离:
总结
brisque 和niqe
brisque 和niqe 来自同个作者,整体的特征提取几乎是一样,主要在后面的处理: